아래 사이트에서 자신의 OS에 맞는 버전을 다운로드
👾 LM Studio - Discover and run local LLMs
Find, download, and experiment with local LLMs
lmstudio.ai
M1에 맞는 버전으로 선택해서 다운로드


설치파일 더블클릭후 "LM Studio" 파일을 Applications 로 Drag&Drop해서 설치합니다. (간단)

설치가 완료되면 응용프로그램에서 해당 실행파일을 찾아서 Double Click 해서 실행합니다.

실행화면...
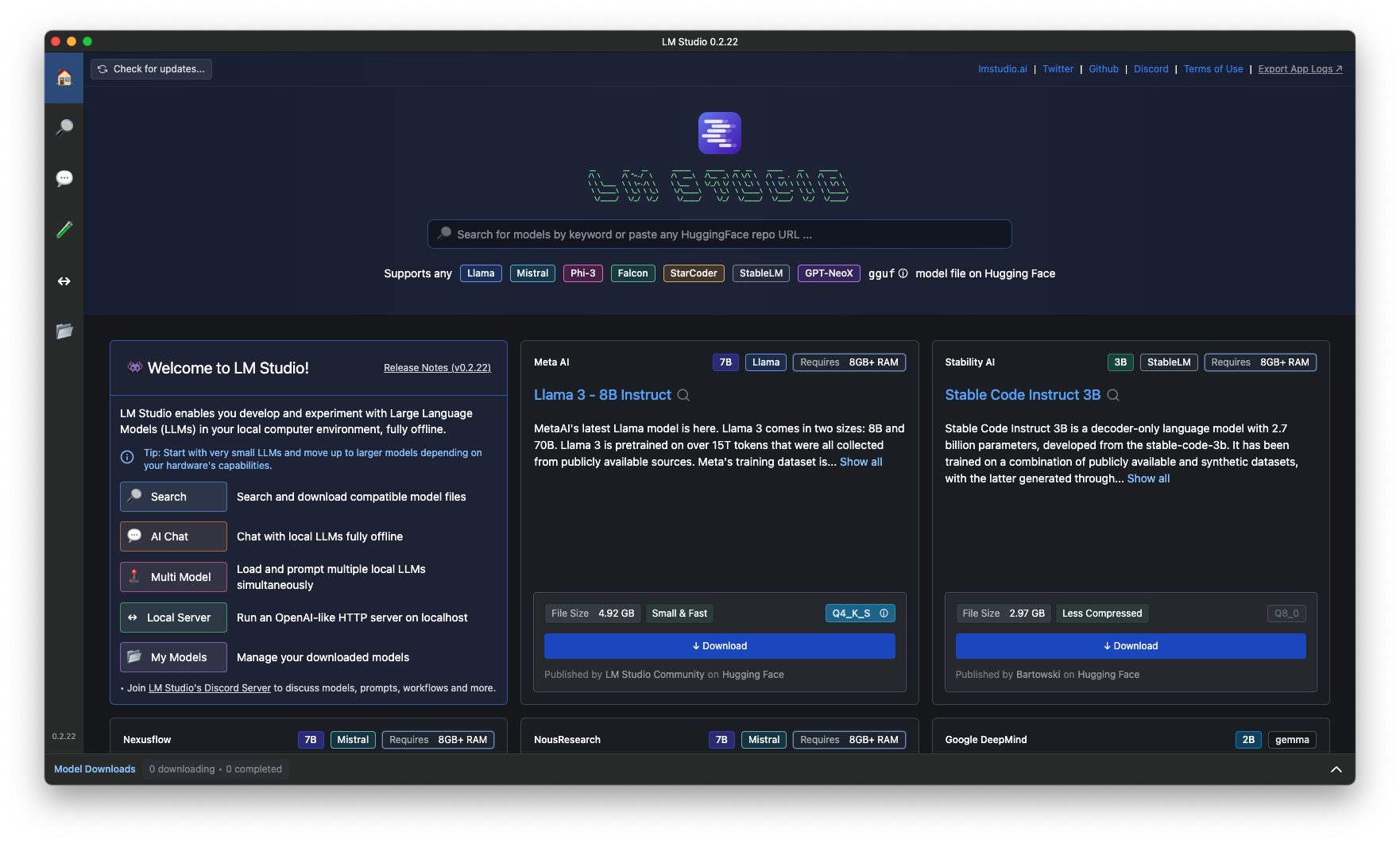
EEVE모델 다운로드 받아서 실행
Teddy Note의 Teddy가 올려놓은 모델을 받아서 구동해보겠습니다.
작업순서
- 먼저 검색창에 HuggingFace의 아이디 "teddylee777"를 입력하고 "Go" 버튼 클릭
- 왼쪽 리스트에서 설치를 원하는 모델을 선택
- 오른쪽 "Available Files에서 본인 PC에 맞는 버전의 gguf 파일을 선택 (초록색으로 표시된 모델이 본인 PC에서 구동가능한 모델)
- "Download" 클릭하면 로컬로 다운로드

다운로드가 표시됨

다운로드 완료

다운로드된 파일 목록 확인

"My Models" 상단에 "Reveal in Finder"를 클릭하면 다운로드된 모델의 임시경로를 확인할수있습니다.

실행을위해서 AI Chat을 선택 > 상단에서 "Select a model to load" 를 선택하면 로컬에 다운로드된 모델을 확인가능
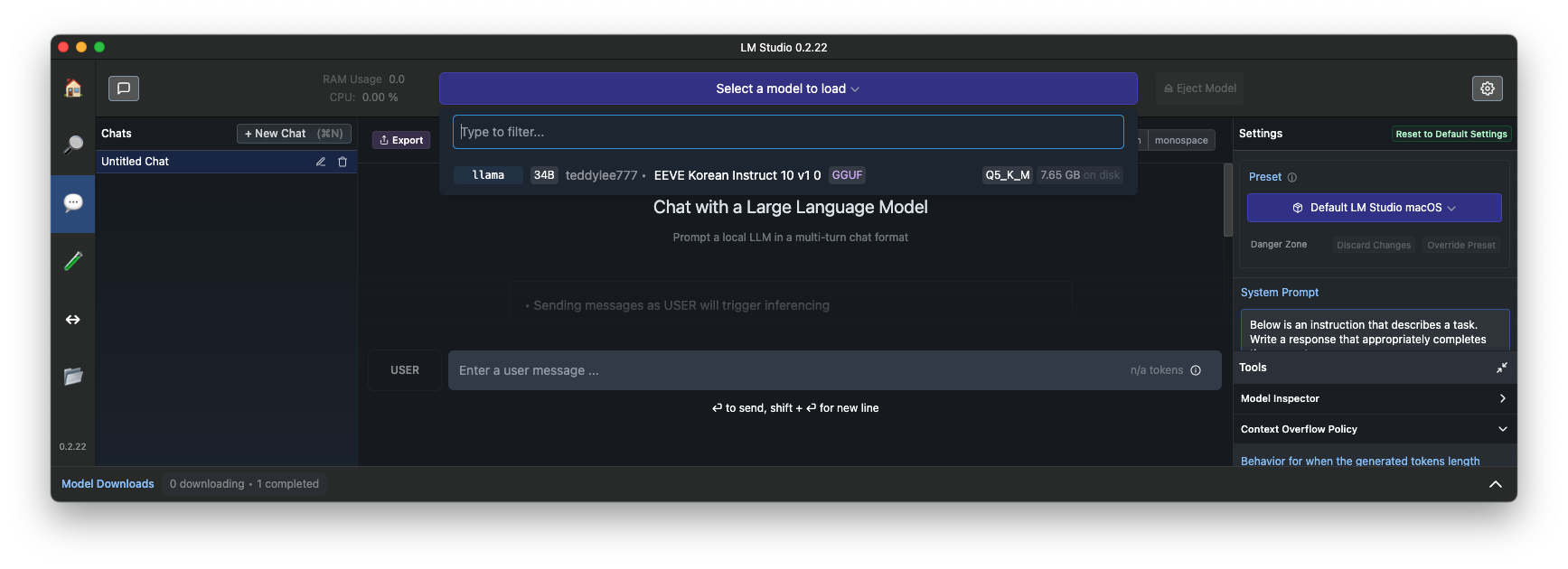
모델을 선택하면, 로컬 모델이 로드됩니다.
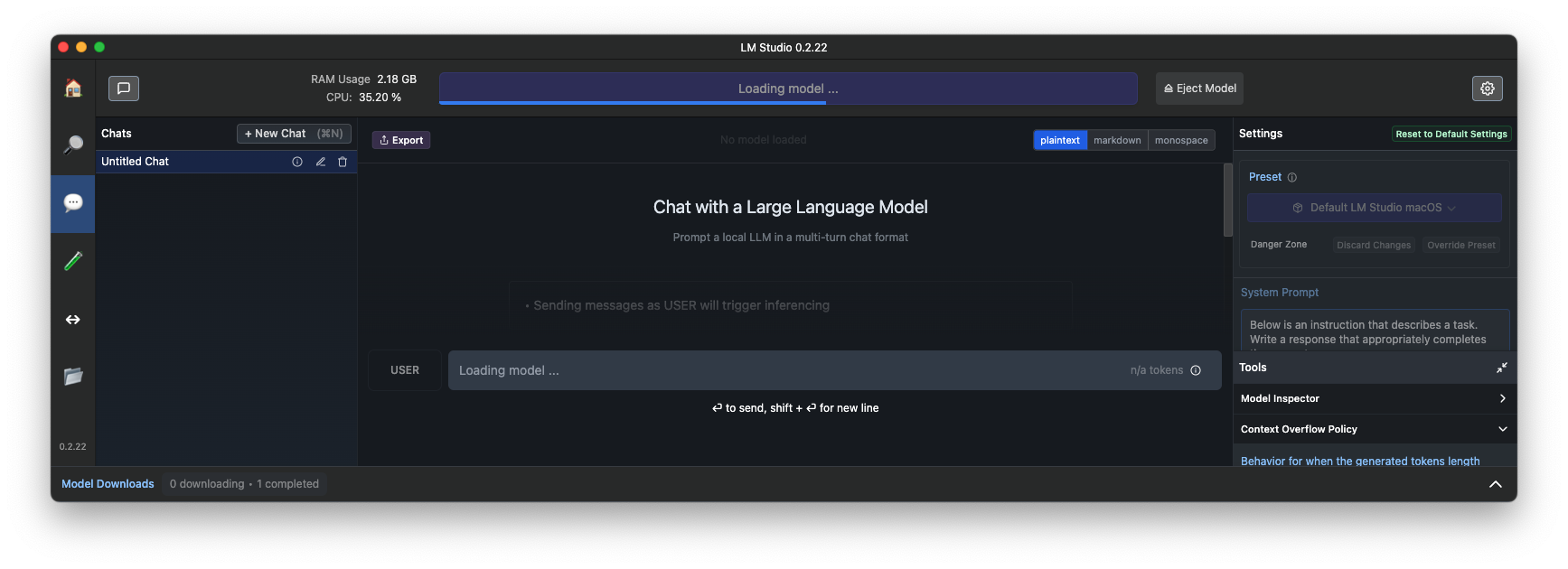
모델 로그가완료되면 로드된 모델을 구동하기외한 Memory, CPU 등이 표시되고 선택된 모델의 정보도 표시가 됩니다.

"대한민국의 수도는 어디야" 로 Query 요청

간결하게 결과가 나왔습니다.


추론도 잘하네요

그런데 GPU를 100% 사용하지 않아서 인지 실행시간이 오래 걸립니다. (47.07s)

Model Preset 설정 변경
/Users/dongsik/.cache/lm-studio/config-presets
% ll
total 192
drwxr-xr-x@ 25 dongsik staff 800 May 3 01:03 .
drwxr-xr-x@ 11 dongsik staff 352 May 2 17:57 ..
-rw-r--r--@ 1 dongsik staff 6148 May 3 01:03 .DS_Store
-rw-r--r--@ 1 dongsik staff 372 May 2 16:09 alpaca.preset.json
-rw-r--r--@ 1 dongsik staff 376 May 2 16:09 chatml.preset.json
-rw-r--r--@ 1 dongsik staff 337 May 2 16:09 codellama_completion.preset.json
-rw-r--r--@ 1 dongsik staff 427 May 2 16:09 codellama_instruct.preset.json
-rw-r--r--@ 1 dongsik staff 457 May 2 16:09 codellama_wizardcoder.preset.json
-rw-r--r--@ 1 dongsik staff 414 May 2 16:09 cohere_command_r.preset.json
-rw-r--r--@ 1 dongsik staff 1896 May 3 01:04 config.map.json
-rw-r--r--@ 1 dongsik staff 511 May 2 16:09 deepseek_coder.preset.json
-rw-r--r--@ 1 dongsik staff 1177 May 2 16:09 default_lm_studio_macos.preset.json
-rw-r--r--@ 1 dongsik staff 433 May 2 16:09 google_gemma_instruct.preset.json
-rw-r--r--@ 1 dongsik staff 540 May 2 16:09 llama_3.preset.json
-rw-r--r--@ 1 dongsik staff 416 May 3 00:52 llama_3_eeve_korean_instruct.preset.json
-rw-r--r--@ 1 dongsik staff 230 May 2 16:09 lm_studio_blank_preset.preset.json
-rw-r--r--@ 1 dongsik staff 392 May 2 16:09 metaai_llama_2_chat.preset.json
-rw-r--r--@ 1 dongsik staff 295 May 2 16:09 mistral_instruct.preset.json
-rw-r--r--@ 1 dongsik staff 412 May 2 16:09 obsidian_vision.preset.json
-rw-r--r--@ 1 dongsik staff 365 May 2 16:09 openchat.preset.json
-rw-r--r--@ 1 dongsik staff 332 May 2 16:09 phi_2.preset.json
-rw-r--r--@ 1 dongsik staff 372 May 2 16:09 phi_3.preset.json
-rw-r--r--@ 1 dongsik staff 402 May 2 16:09 phind_codellama.preset.json
-rw-r--r--@ 1 dongsik staff 453 May 2 16:09 vicuna_v1_5_16k.preset.json
-rw-r--r--@ 1 dongsik staff 360 May 2 16:09 zephyr.preset.json
%
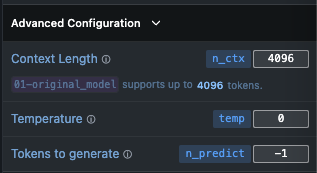
Modelfile
FROM EEVE-Korean-Instruct-10.8B-v1.0-Q8_0.gguf
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER temperature 0
PARAMETER num_predict 3000
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>
변경된 Preset을 다른이름으로 저장
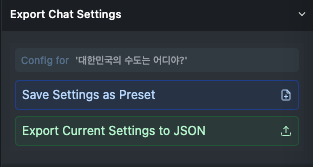
"Save Settings as Preset"을 클릭하고 저장하고싶은 Preset 이름을 지정합니다.

/Users/dongsik/.cache/lm-studio/config-presets
% ll llama*
-rw-r--r--@ 1 dongsik staff 540 May 2 16:09 llama_3.preset.json
-rw-r--r--@ 1 dongsik staff 416 May 3 00:52 llama_3_eeve_korean_instruct.preset.json
%
% cat llama_3_eeve_korean_instruct.preset.json
{
"name": "Llama 3 EEVE Korean Instruct",
"inference_params": {
"input_prefix": "\n<s>Human:",
"input_suffix": "</s>\n<s>Assistant:",
"pre_prompt": "You are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.",
"pre_prompt_prefix": "<s>",
"pre_prompt_suffix": "</s>",
"antiprompt": [
"<s>",
"</s>"
]
}
}
질문


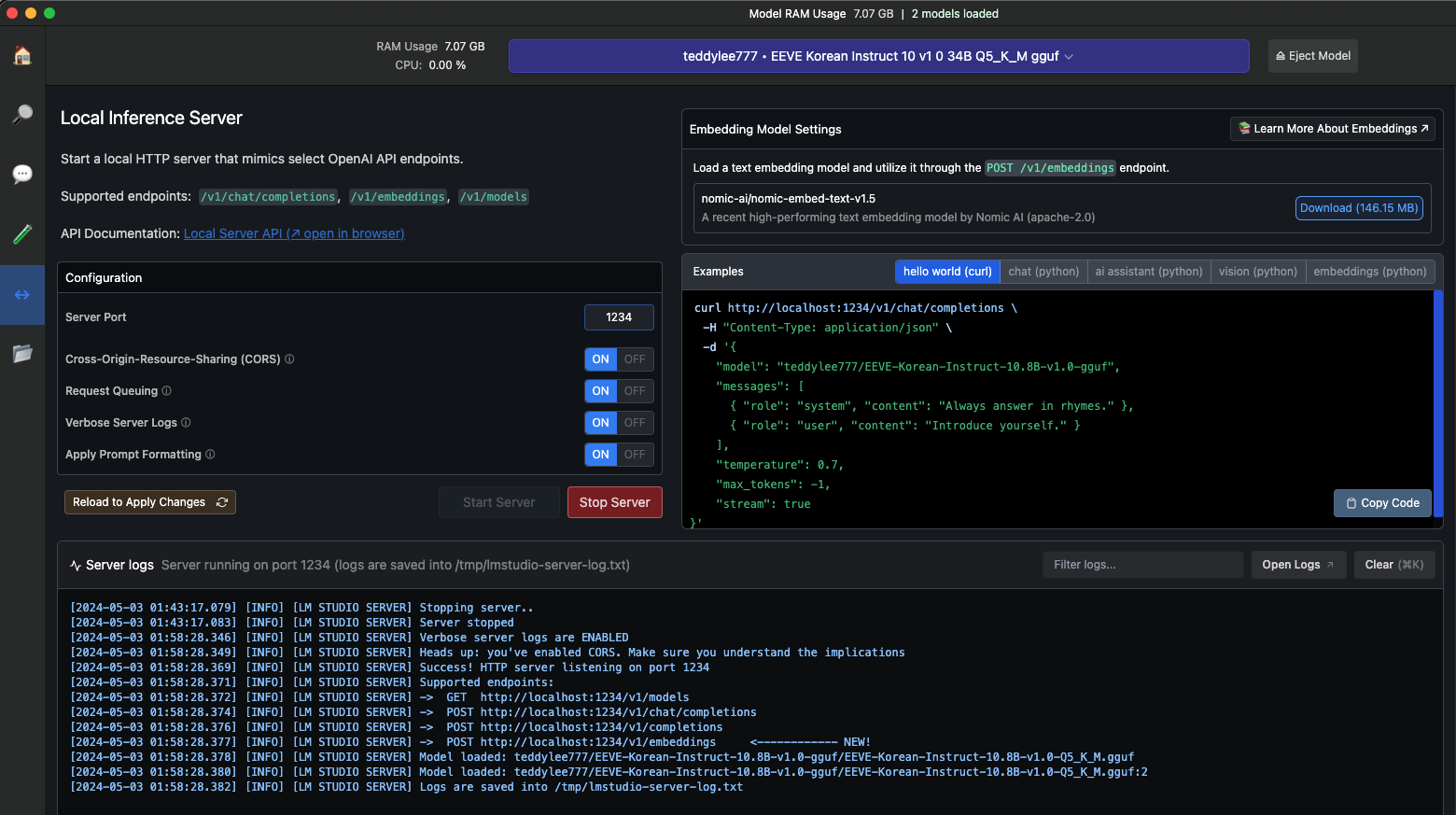
CPU 사용률 100% 가까이 사용하면서 응답 속도가 빨라졌네요.

Local Inference Server
from langchain_openai import ChatOpenAI
from langchain_core.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio",
#model="teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf",
model="teddylee777/EEVE-Korean-Instruct-10.8B-v1.0-gguf/EEVE-Korean-Instruct-10.8B-v1.0-Q5_K_M.gguf",
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()], # 스트리밍 콜백 추가
)
prompt = PromptTemplate.from_template(
"""You are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.
You must generate an answer in Korean.
#Question:
{question}
#Answer: """
)
chain = prompt | llm | StrOutputParser()
response = chain.invoke({"question": "대한민국의 수도는 어디입니까?"})
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.
You must generate an answer in Korean.
#Question:
대한민국의 수도는 어디입니까?
#Answer:
### Response:
대한민국의 수도는 서울특별시입니다.
response = chain.invoke({"question": "한국의 수도는 어디인가요? 아래 선택지 중 골라주세요.\n\n(A) 경성\n(B) 부산\n(C) 평양\n(D) 서울\n(E) 전주"})Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.
You must generate an answer in Korean.
#Question:
한국의 수도는 어디인가요? 아래 선택지 중 골라주세요.
(A) 경성
(B) 부산
(C) 평양
(D) 서울
(E) 전주
#Answer:
### Response:
대한민국의 수도는 (D) 서울입니다.
참고
'AI > LLM' 카테고리의 다른 글
| M1 LM Studio를 위한 Command Line Tool lms 설치 (0) | 2024.05.04 |
|---|---|
| GPT-4 비전과 LLaVA (0) | 2024.05.04 |
| RAG(Retrieval Augmented Generation)를 활용하여 텍스트, 테이블, 이미지 처리하기 (0) | 2024.05.02 |
| M1 Ollama로 Model 테스트 (0) | 2024.04.25 |
| M1 Ollama로 Llama3 8B 모델 테스트 (0) | 2024.04.24 |