관심가는 주제가 있어서 내용 읽어보면서 번역해봅니다.
http://www.nltk.org/book_1ed/ch07.html
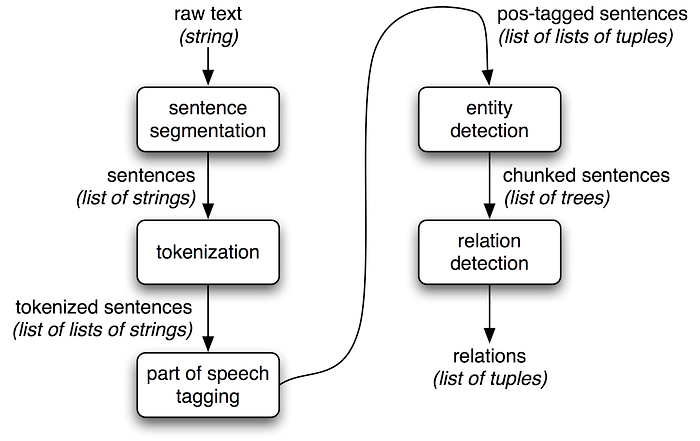
텍스트에서 정보를 추출하는 간단한 방법은 다음과 같습니다.
- 텍스트를 문장으로 분할하기
- 그 다음 문장을 단어로 토큰화하기 (tokenize)
- 각 토큰의 품사(part-of-speech)를 파악하기 (이는 다음 단계를 가능하게 함)
- 개체 탐지하기 (Entity detection)
- 마지막으로 서로 다른 개체/토큰 간의 관계 파악하기
이러한 단계들을 통해, 우리는 의미 있는 정보를 추출할 수 있게 됩니다. 이 정보는 추가적인 처리에 사용할 수 있으며, 주제 감정 탐지(subject sentiment detection), 주제 식별(theme identification), 사전 생성(dictionary creation) 텍스트 태깅(text tagging) 등과 같은 더 정교한 작업을 수행하는 데 활용할 수 있습니다.
이 짧은 글을 통해, 우리는 5단계 정보 추출 과정의 기본 구성 요소를 형성하는 **문법 청킹(Grammar Chunking)**을 탐구하고자 합니다.
문법 청킹(Grammar Chunking)은 문장에서 다중 토큰 구문(pharses)을 품사 태깅과 함께 추출하는 기술입니다. 문장은 문장(Setence) → 절(Clauses) → 구(Pharses) → 단어(Words)로 구성된 계층적 문법 구조를 따릅니다. 청킹은 사용자가 의식적으로 또는 무의식적으로 찾고 있는 품사 태그 패턴을 기반으로 문장의 일부, 즉 구를 선택합니다.
예를 들어, 모든 문장에는 다섯 가지 주요 "의미 있는 구" 범주가 있습니다 - 명사구(NP), 동사구(VP), 형용사구(ADJP), 부사구(ADVP), 전치사구(PP). 이러한 구 유형을 텍스트에서 추출하고 더 나아가 관계를 설정하거나 개체를 식별하거나 필요에 따라 필터링하면, 80%의 경우에 이 간단한 추출만으로도 텍스트 데이터를 이해하고 다른 NLP 작업을 진행하는 데 필요한 정보를 얻을 수 있습니다.
전통적으로 문법 청킹을 수행하는 다양한 방법이 있습니다:
- 태그 패턴
- 정규 표현식을 이용한 청킹(Chunking)
- 텍스트 말뭉치(Corpora)
- 규칙 기반 청킹
- 통계 기반 청킹
우리는 이를 새로운 응용 머신러닝 관점에서 살펴볼 것입니다. 모든 프로그래밍 복잡성을 숨기기 위해 - 우리는 spaCy 라이브러리를 사용할 것입니다 (spaCy는 고급 NLP를 위한 무료 오픈 소스 라이브러리입니다. 빠르고 정확합니다). 이 라이브러리는 위에서 나열한 5단계를 수행하기 위한 매우 사용하기 쉬운 인터페이스를 제공합니다.
물론, 내장 라이브러리의 경우와 마찬가지로 우리는 특정한 유연성을 잃게 되지만, 일부 유연성을 회복하기 위해 추가적인 프로그래밍을 어떻게 구축하는지도 간단히 다룰 것입니다.
우리는 해결책을 개발하기 위해 Python과 Jupyter Notebook을 사용할 것입니다. 데이터는 스크랩한 샘플 뉴스 기사가 될 것입니다. Jupyter Notebook과 사용된 샘플 데이터는 GitHub에서 액세스할 수 있습니다.
(이 접근 방식을 통해 실제 데이터로 작업하면서 spaCy를 사용한 NLP 작업을 실습할 수 있습니다. GitHub 저장소를 통해 코드와 데이터를 쉽게 공유하고 접근할 수 있어, 다른 사람들도 이 예제를 따라 해볼 수 있습니다.)
몇 가지 필요한 라이브러리를 임포트하는 것으로 시작하겠습니다.
import pandas as pd, os, re, string
import numpy as np
import spacy
#'en_core_web_md' is a General-purpose pretrained model to predict named entities,
#part-#of-speech tags and syntactic dependencies.
#Can be used out-of-the-#box and fine-tuned on more specific data.
nlp = spacy.load('en_core_web_md')
comp=pd.read_excel(r'C:\Saurabh\Publication\Chunking\Chunk_data.xlsx')
print(len(comp))
print(comp.dtypes)
print(comp['Text'].astype(str))
2
Text object
dtype: object
0 Ruth Bader Ginsburg was an associate justice o...
1 I opened a savings account at Wells Fargo in D...
Ruth Ginsberg에 관한 첫 번째 샘플 단락을 사용하여 개념을 설명하겠습니다. 참고로, 우리는 'en_core_web_md'라는 spaCy의 범용 사전 학습된 모델을 사용하여 명명된 엔티티(named entities), 품사 태그(part-of-speech tags), 구문적 의존성(syntactic dependencies)을 예측합니다. 이 모델은 바로 사용할 수 있으며, 더 특정한 데이터에 맞춰 미세 조정할 수도 있습니다.
이제 문장 토크나이저를 사용하여 문장을 추출해보겠습니다.
comp['sentence'] = comp['Text'].apply(lambda x: sent_tokenize(x))
print(len(comp['sentence'][0]))
comp['sentence_clean'] = comp['sentence']
print(comp['sentence_clean'])
comp_subset = pd.DataFrame(comp['sentence_clean'][0], columns=['sentence_clean'])
comp_subset
2
0 [Ruth Bader Ginsburg was an associate justice ...
1 [I opened a savings account at Wells Fargo in ...
텍스트를 문장 목록으로 변환한 것을 볼 수 있습니다. 확장 가능한 프로세스를 설정하기 위해 문장을 세로형 Dataframe으로 변환합니다. 샘플 단락에 대해 설정하고 있지만, 이 작업의 목적을 이해하시리라 생각합니다. 이 방식은 여러 단락과 문장에 대해 적용할 수 있습니다.
comp_subset = pd.DataFrame(comp['sentence_clean'][0], columns=['sentence_clean'])
comp_subset
이제 다음 두 단계를 진행하겠습니다. 단어 토큰화(tokenization)와 품사 태깅(POS tagging)입니다. spaCy를 사용하면 이 작업이 얼마나 쉬운지 확인해보세요. onegram 메서드는 단어(토큰), 품사 태깅, 그리고 텍스트 분석 작업에서 유용한 다양한 정보를 출력합니다. 또한 이 메서드가 토큰과 품사를 어떻게 반환하는지도 주목해보세요. 나중에 n-grams을 생성해야 할 경우, n-grams과 품사 태깅을 생성하는 방법으로 이 메서드를 확장하는 방법도 보여드리겠습니다.
def onegram(text):
doc = nlp(text)
result = []
print("{0:20} {1:20} {2:8} {3:8} {4:8} {5:8} {6:8} {7:8}".format("text", "lemma_", "pos_", "tag_", "dep_",
"shape_", "is_alpha", "is_stop"))
for token in doc:
print("{0:20} {1:20} {2:8} {3:8} {4:8} {5:8} {6:8} {7:8}".format(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop))
#print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
#token.shape_, token.is_alpha, token.is_stop)
result.append((token.text, token.tag_))
return result
comp_subset = comp_subset[comp_subset.index==0]
comp_subset.head(1)['sentence_clean'].apply(onegram)

이 메서드는 실제 토큰(예: "was"), 어간(즉, 토큰의 기본형, 예: "be"), 품사(AUX), 품사 태깅(VBD), 문장에서 다른 단어에 대한 의존성(ROOT), 형태(즉, 소문자로 시작하는지, 알파벳만 있는지, 그리고 불용어인지 여부)를 제공합니다. 단 두 줄의 코드로 이 모든 정보를 얻을 수 있다는 것은 정말 놀랍습니다! 만약 NLTK를 사용해 본 적이 있다면, 이러한 정보를 얻기 위해 얼마나 많은 코드를 작성해야 하는지 아실 겁니다. 그리고 이 정보들은 매우 중요합니다. 불용어를 제거하고, 알파벳이 아닌 텍스트를 정리하며, 텍스트를 표제화(lemmatize)하고, 패턴을 교정하는 데 사용할 수 있습니다.
이제 우리의 목표로 돌아가서, 우리는 토큰과 품사를 얻었습니다. 그렇다면 한 단계 더 나아가 특정 패턴을 가진 단어 그룹(예: 명사구)을 식별할 수 있는 방법은 무엇일까요? 명사구(NP)는 선택적 한정사(DT) 뒤에 여러 형용사(JJ)가 오고 그 다음에 명사(NN)가 오는 단어들의 연속입니다.
def extractNP(text):
doc = nlp(text)
result = []
for np in doc.noun_chunks:
result.append(np.text)
print(result)
return result
comp_subset['sentence_clean'].apply(extractNP)
['Ruth Bader Ginsburg', 'an associate justice', 'the U.S. Supreme Court', 'nearly three decades']
이 출력은 문장 내의 모든 명사구를 보여줍니다. spaCy는 내장된 명사 청커를 제공하지만, 동사구, 형용사구 또는 특정 문법 패턴에 기반한 구가 필요한 경우, spaCy가 제공하는 토큰과 품사 정보를 사용하여 사용자 정의 함수를 만들 수 있습니다.
이제 정보 추출의 다음 단계로 넘어가 보겠습니다 - 서로 다른 토큰 간의 구문적 관계(syntactic relationship detection)를 탐지하는 것입니다. 이를 통해 우리는 문장 구조를 더 잘 이해하고 필요에 따라 특정 부분을 선택적으로 활용할 수 있습니다.
from spacy import displacy
def getdependency(text):
doc = nlp(text)
print("{0:20} {1:20} {2:20} {3:20} {4:30}".format("text", "dep_", "head", "head_pos_", "children"))
for token in doc:
print("{0:20} {1:20} {2:20} {3:20} {4:30}".format(token.text, token.dep_, token.head.text, token.head.pos_,
" ".join([str(child) for child in token.children])))
return
def getdisplay(text):
doc = nlp(text)
displacy.serve(doc, style="dep")
return
comp_subset['sentence_clean'].apply(getdependency)
comp_subset['sentence_clean'].apply(getdisplay)


테이블과 시각 자료를 모두 읽어 head, children, 그리고 의존성을 이해할 수 있어야 합니다. 이 문장의 일부에서 Ginsburg는 명사 주어이며, Ruth와 Bader 모두 이에 의존합니다. "was"는 Ruth를 그녀의 직업인 justice(associate justice)와 연결하는 root입니다. 이는 문장의 일부에 대한 매우 간단한 해석입니다 - 다양한 열 제목의 의미를 이해하기 위해 추가 학습을 하시기를 권합니다. 그래야 직접 더 잘 해석할 수 있는 위치에 있게 될 것입니다.
관계 탐지는 중요하고 유용합니다 - 예를 들어, 감정 분석을 수행하고 있고 각 주제에 대한 작성자의 감정을 이해해야 한다고 가정해 봅시다. 이런 시나리오에서는 각 주제와 그 주제와 관련된 단어들을 식별할 수 있는 능력이 핵심이 됩니다.
마지막 부분인 개체 탐지로 넘어가겠습니다. 명명된 개체는 이름이 지정된 "실제 세계의 객체"입니다 - 예를 들어, 사람, 국가, 제품 또는 책 제목 등입니다. spaCy는 모델에 예측을 요청함으로써 문서 내의 다양한 유형의 명명된 개체(named entities)를 인식할 수 있습니다. 모델은 통계적이며 학습된 예제에 크게 의존하기 때문에, 이것이 항상 완벽하게 작동하는 것은 아니며 사용 사례에 따라 나중에 약간의 조정이 필요할 수 있습니다.
예를 들어, 문서 파싱 문제(예: 이력서 파싱)에 대해 작업하고 있고 사람이 공부한 학교 이름과 위치를 식별해야 한다고 가정해 봅시다. 이런 경우 개체 탐지가 유용할 것입니다. 이를 통해 문장을 실제 세계의 정보와 연결할 수 있습니다.
def getEntity(text):
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
return
comp_subset['sentence_clean'].apply(getEntity)

개체 탐지를 통해 이제 Ruth Bader Ginsburg를 사람으로, U.S. Supreme Court를 조직으로 식별할 수 있습니다! 그리고 관계 탐지를 통해 Ruth가 associate justice라는 것을 알 수 있습니다. 따라서 이제 여러분과 기계는 Ruth Bader Ginsburg가 U.S. Supreme Court의 associate justice라는 것을 알 수 있게 되었습니다!
이 글이 마음에 들고 도움이 된다고 생각하신다면, 박수를 보내주세요!
저자 소개
Dr. Mahendra Nayak와 Mr. Saurabh Singh는 Accenture Applied Intelligence, 방갈로르의 수석 데이터 과학자입니다. 그들은 주로 대규모 비정형 데이터, 예측 모델링, 기계 학습, 그리고 기업 규모의 지능형 시스템 구축 분야에서 일하고 있습니다.
https://medium.com/@saurabhsingh_23777/grammar-chunking-and-text-information-extraction-140cd796d73b
Grammar Chunking and Text Information Extraction
Author: Dr. Mahendra Nayak and Saurabh Singh
medium.com
'AI > LLM' 카테고리의 다른 글
| Multi Modal RAG를 위한 다중문서 처리 모듈 unstructured 살펴보기 (0) | 2024.05.07 |
|---|---|
| 대용량 PDF를 위한 unstructured와 Multi-modal RAG에 대한 심층 분석 (0) | 2024.05.06 |
| OpenAI LLM, FAISS , Langchain, streamlit 으로 RAG 구현 (1) | 2024.05.04 |
| M1 LM Studio를 위한 Command Line Tool lms 설치 (0) | 2024.05.04 |
| GPT-4 비전과 LLaVA (0) | 2024.05.04 |