RAG(Retrieval Augmented Generation)를 활용하여 텍스트, 테이블, 이미지 처리하기
정보 검색 영역에서, 검색 증강 생성(RAG)은 방대한 텍스트 데이터에서 지식을 추출하는 강력한 도구로 부상했습니다. 이 다재다능한 기법은 관련 문서에서 정보를 효과적으로 요약하고 종합하는 데 있어 검색 및 생성 전략의 조합을 활용합니다. 그러나 RAG가 상당한 추이를 보였음에도 불구하고, 텍스트, 표, 이미지와 같은 더 넓은 범위의 콘텐츠 유형에 대한 적용은 상대적으로 탐색되지 않았습니다.
멀티모달 콘텐츠의 과제
대부분의 실제 문서는 텍스트, 표, 이미지와 같은 다양한 정보를 결합하여 복잡한 아이디어와 통찰을 전달합니다. 전통적인 RAG 모델은 텍스트 처리에 탁월하지만, 다중 모달 콘텐츠를 효과적으로 통합하고 이해하는 데 어려움을 겪습니다. 이러한 제한은 RAG가 이러한 문서의 본질을 완전히 포착하는 능력을 방해하여, 불완전하거나 부정확한 표현으로 이어질 수 있습니다.
이 포스트에서는 이러한 문서를 처리할 수 있는 다중 모달 RAG를 생성하는 방법을 살펴보겠습니다.
다음은 이러한 문서를 처리하는 데 사용할 그래프입니다.
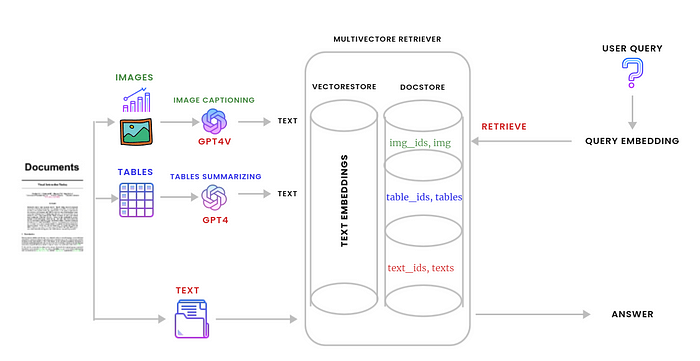
단계 1: 원시 요소로 파일 분할. (Split the file to raw elements.)
첫째, 환경에 필요한 모든 라이브러리를 가져옵니다.
import os
import openai
import io
import uuid
import base64
import time
from base64 import b64decode
import numpy as np
from PIL import Image
from unstructured.partition.pdf import partition_pdf
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, SystemMessage
from langchain.vectorstores import Chroma
from langchain.storage import InMemoryStore
from langchain.schema.document import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from operator import itemgetter
Unstructured를 사용하여 문서(PDF)의 이미지, 텍스트 및 표를 구문 분석할 것입니다. 이 코드를 이 Google Colab에서 직접 실행하거나 여기에서 PDF 파일을 다운로드하여 세션 저장소에 업로드할 수 있습니다. 아래 단계를 따르세요.
(코드를 실행하기 전에 venv를 설정하려면 google colab의 설치 지침을 참조하세요.)
# load the pdf file to drive
# split the file to text, table and images
def doc_partition(path,file_name):
raw_pdf_elements = partition_pdf(
filename=path + file_name,
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path)
return raw_pdf_elements
path = "/content/"
file_name = "wildfire_stats.pdf"
raw_pdf_elements = doc_partition(path,file_name)
위 코드를 실행하면 파일에 포함된 모든 이미지가 추출되어 해당 경로에 저장됩니다.
Google Colab의 경우(경로 = “/content/”)
다음으로 각 원시 요소를 해당 카테고리에 추가합니다 (텍스트는 텍스트로, 테이블은 테이블로, 이미지의 경우 구조화되지 않은 항목이 이미 처리되었습니다..).
# appending texts and tables from the pdf file
def data_category(raw_pdf_elements): # we may use decorator here
tables = []
texts = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
texts.append(str(element))
data_category = [texts,tables]
return data_category
texts = data_category(raw_pdf_elements)[0]
tables = data_category(raw_pdf_elements)[1]
2단계: 이미지 캡션(Image captioning) 작성 및 표 요약 (Table summarizing)
테이블을 요약하기 위해 Langchain과 GPT-4를 사용합니다. 이미지 캡션을 생성하려면 GPT-4-Vision-Preview를 사용합니다. 이는 현재 여러 이미지를 함께 처리할 수 있는 유일한 모델이기 때문이며, 이는 여러 이미지가 포함된 문서에 중요합니다. 텍스트 요소의 경우 임베딩으로 만들기 전에 그대로 둡니다.
OpenAI API 키를 준비하세요
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxx'
openai.api_key = os.environ["OPENAI_API_KEY"]
# function to take tables as input and then summarize them
def tables_summarize(data_category):
prompt_text = """You are an assistant tasked with summarizing tables. \
Give a concise summary of the table. Table chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
model = ChatOpenAI(temperature=0, model="gpt-4")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
return table_summaries
table_summaries = tables_summarize(data_category)
text_summaries = texts
이미지의 경우 캡션을 위해 모델에 공급하기 전에 base64 형식으로 인코딩해야 합니다.
def encode_image(image_path):
''' Getting the base64 string '''
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def image_captioning(img_base64,prompt):
''' Image summary '''
chat = ChatOpenAI(model="gpt-4-vision-preview",
max_tokens=1024)
msg = chat.invoke(
[
HumanMessage(
content=[
{"type": "text", "text":prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img_base64}"
},
},
]
)
]
)
return msg.content
이제 image_base64 목록을 추가하고 요약한 다음 base64로 인코딩된 이미지와 관련 텍스트를 분할할 수 있습니다.
아래 코드를 실행하는 동안 오류 코드 429와 함께 이 RateLimitError가 발생할 수 있습니다. 이 오류는 조직의 gpt-4-vision-preview에 대한 분당 요청(RPM) 속도 제한을 초과했을 때 발생합니다. 제 경우에는 3RPM의 사용 제한이 있으므로 각 이미지 캡션을 작성한 후 안전 조치로 60초를 설정하고 속도 제한이 재설정될 때까지 기다립니다.
# Store base64 encoded images
img_base64_list = []
# Store image summaries
image_summaries = []
# Prompt : Our prompt here is customized to the type of images we have which is chart in our case
prompt = "Describe the image in detail. Be specific about graphs, such as bar plots."
# Read images, encode to base64 strings
for img_file in sorted(os.listdir(path)):
if img_file.endswith('.jpg'):
img_path = os.path.join(path, img_file)
base64_image = encode_image(img_path)
img_base64_list.append(base64_image)
img_capt = image_captioning(base64_image,prompt)
time.sleep(60)
image_summaries.append(image_captioning(img_capt,prompt))
def split_image_text_types(docs):
''' Split base64-encoded images and texts '''
b64 = []
text = []
for doc in docs:
try:
b64decode(doc)
b64.append(doc)
except Exception as e:
text.append(doc)
return {
"images": b64,
"texts": text
}
3단계: 다중 벡터 검색기(Multi-vector retriever)를 만들고 Vectore Base에 텍스트, 테이블, 이미지 및 해당 인덱스를 저장
첫 번째 파트를 완료했습니다. 이는 문서를 원시 요소로 분할하고, 표 및 이미지를 요약하는 과정을 포함합니다. 이제 두 번째 파트로 넘어가서 멀티-벡터 리트리버를 생성하고, part one에서 생성된 결과물을 chromadb에 id와 함께 저장할 것입니다.
1. 하위 청크(summary_texts,summary_tables, summary_img)를 인덱싱하기 위해 벡터스토어를 생성하고 임베딩을 위해 OpenAIEmbeddings()를 사용합니다.
2. (doc_ids, texts), (table_ids, tables) 및 (img_ids, img_base64_list)를 저장할 상위 문서에 대한 docstore
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="multi_modal_rag",
embedding_function=OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Add image summaries
img_ids = [str(uuid.uuid4()) for _ in img_base64_list]
summary_img = [
Document(page_content=s, metadata={id_key: img_ids[i]})
for i, s in enumerate(image_summaries)
]
retriever.vectorstore.add_documents(summary_img)
retriever.docstore.mset(list(zip(img_ids, img_base64_list)))
4단계: langchain RunnableLambda를 사용하여 위의 모든 내용을 래핑
- 먼저 컨텍스트(이 경우 "텍스트"와 "이미지" 모두)와 질문(여기에서는 RunnablePassthrough만)을 계산합니다.
- 그런 다음 이를 gpt-4-vision-preview 모델에 대한 메시지 형식을 지정하는 사용자 정의 함수인 프롬프트 템플릿에 전달합니다.
- 마지막으로 출력을 문자열로 구문 분석합니다.
from operator import itemgetter
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
def prompt_func(dict):
format_texts = "\n".join(dict["context"]["texts"])
return [
HumanMessage(
content=[
{"type": "text", "text": f"""Answer the question based only on the following context, which can include text, tables, and the below image:
Question: {dict["question"]}
Text and tables:
{format_texts}
"""},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{dict['context']['images'][0]}"}},
]
)
]
model = ChatOpenAI(temperature=0, model="gpt-4-vision-preview", max_tokens=1024)
# RAG pipeline
chain = (
{"context": retriever | RunnableLambda(split_image_text_types), "question": RunnablePassthrough()}
| RunnableLambda(prompt_func)
| model
| StrOutputParser()
)
이제 Multi-retrieval Rag를 테스트할 준비가 되었습니다.
chain.invoke(
"What is the change in wild fires from 1993 to 2022?"
)
대답은 다음과 같습니다.
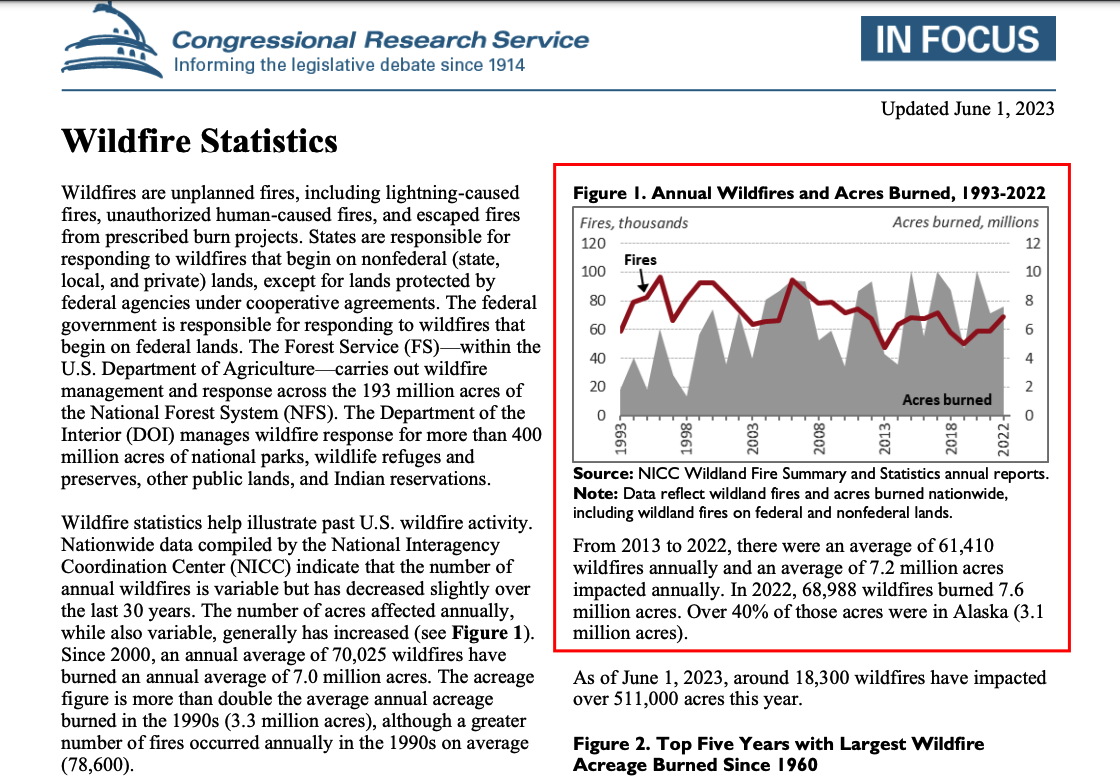
Based on the provided chart, the number of wildfires has increased from 1993 to 2022. The chart shows a line graph with the number of fires in thousands, which appears to start at a lower point in 1993 and ends at a higher point in 2022. The exact numbers for 1993 are not provided in the text or visible on the chart, but the visual trend indicates an increase.
Similarly, the acres burned, represented by the shaded area in the chart, also show an increase from 1993 to 2022. The starting point of the shaded area in 1993 is lower than the ending point in 2022, suggesting that more acres have been burned in 2022 compared to 1993. Again, the specific figures for 1993 are not provided, but the visual trend on the chart indicates an increase in the acres burned over this time period.to do
pdf 내용
References :
https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector